Risk Scoring
This section covers how Risk Scoring is performed.
Overview
Fluency uses an open ending scoring system, which scores risk based on learning, behavioral categorization, askew-prevention, and fault tolerance algorithms. The foundation of the risk scoring system is a traditional severity-based scoring system. The system then considers behavioral models to add additional insight beyond the deployed products detection. Lastly, the system includes a suppression mechanism to capture analyst feedback in improving This combination of has proven to be highly effective in highlighting events that require review.
Why Not a Simple Scoring System?
Early SIEM solutions used a network operation’s approach to security alerts by assigning a label hierarchy. Two popular hierarchies are:
- Status Labeling: information, warning, error, and critical.
- Impact Labeling: low, medium, high, and critical.
The system then sorts alerts by label and presents the list of issues to the analyst. This is still common today, and the result are high-false positives, detection-gaps, and information overload. Attempts to use simple point systems of aggregating the alerts by flows, systems, or user have reduced the number of alerts, for they are now grouped, but demonstrate the same results.
There are a significant number of reasons why this solution fails. The core reason is that alerts are analyzed atomically. Atomic means that the event is valued without any other consideration of the environment, history, or other messages.
Algorithm Stack
Fluency uses multiple algorithms to generate and adjust risk scoring.
- Severity Categorization
- Learning
- Behaviors
- Vectors
- Fault Tolerance
- Askew Prevention
- Suppression
Severity Categorization
Impact severity is the start of the Fluency scoring system. While any tag can be added to the signature, there are defined tags that are related to the impact severity.
These start with ‘ALERT_SEVERITY’ and completed with the level:
- Low
- Medium
- High
- Critical
There are also tags to the risk to provide further categorization. These start with ‘ALERT’ and completed with their descriptor:
- Normal
- Endpoint
- High Confidence
- Malware
- Policy
The tags can be combined, meaning that there can be alerts with a series of risk tags:
- ALERT_SEVERITY_CRITICAL,
- ALERT_HIGH_CONFIDENCE,
- ALERT_MALWARE
Risk tags are used for both scoring, searching, and reporting.
For example, policy violations, like login into a system using just a username and password, are not something that would normally trigger an incident response. However, having a report on users who are active and not using multi-factors would be useful. This can be done by tagging events with the ALERT_POLICY and then using those alerts to create a report.
Banded Ordinal Risk Score
Fluency uses a banded ordinal scale to label risk. Ordinal means that the enumerated type has a hierarchy articulated as order. In this case the enumerated types range from ‘none’ to ‘critical’. Banded means that the value of the enumerated types is scaled by a numeric value, in this case called Risk Score. The values for the top of each band are as follows:
| Score Range | Category |
|---|---|
| 0 | None |
| 1 - 1000 | Low |
| 1001 - 2000 | Medium |
| 2001 - 4000 | Serious |
| 4001 - 8000 | High |
| Greater than 8000 | Critical |
Fluency groups scored alerts into a single grouping based on a UEBA key. In this example, the key is the AWS username. The Risk Score value is the aggregated value of all its behaviors. In this example, the two (2) mediums and two (2) serious behaviors combine to give a ‘High’ score for the grouping.
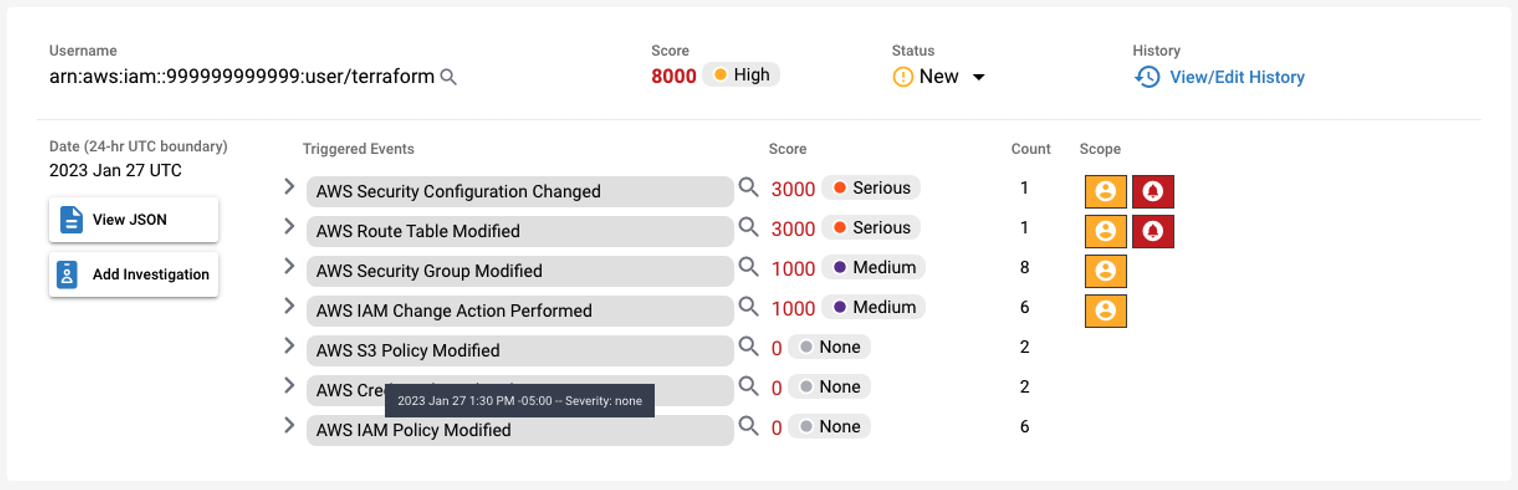
Scored Event
To the right of each behavior, there may appear entity or alert behavior markers. The markers highlight unique events.
- Yellow, Local: The marker is unique for this UEBA key.
- Red, Global: The marker is the first time seen for this organization.
In this example, there are red alerts that represent alerts that have not been seen by this organization in the learning window. Also, this user has not triggered all the behaviors marked with yellow.
The context of uniqueness is important in security. Malicious activity is not normal, it is a fault of the security system that someone is bypassing it. So, while an individual alert that is uncommon should be reviewed, a group of uncommon behavior has a higher risk. It is this combination of abnormal activity combined with fault analysis that makes risk score powerful.
Purpose of None, Low, and Medium Alerts
Marking audit events with critical, high, or high confidence means that this event needs to be validated. Validating the event is the main job of the analyst. How does an analyst validate a key event?
The use of lower impact alerts, such as those marked with none, low, or medium, allow an analyst a means to make an educated determination of validity for an event. This process is how endpoint detection and response (EDR) systems can make decisions in the cloud.
In a validation process, incoming data is roughly divided into three categories:
It is possible to have more than one key event triggering.
Validating a Response with Indicators
When the key event is reviewed, a time window around the key(s) events is created. In this window, a list of indicators support is included to support the key event. For example, a process performs a root escalation. The window is reviewed and determine that a list of events have occurred that supports the key event as worthy to be responded to.
The validation process does not actually validate the key event, it is validating that a response is required.
Suppressing an Alert with Indicators
Suppressors remove possible indicators or key events from being considered malicious or an issue. Let’s say that the previous event was investigated and determined that the unregistered software was BigFix, a patching software agent. The ticket is closed, but just as important a suppression signature is added to the system.
The next time there is an alert, the suppression acts like the opposite of an indicator. It lets the analyst know that the key event is not valid.
Suppression in Fluency
In Fluency, suppression is added into the scoring. It is also common to create ‘timeline’ events that show a proper behavior that acts like a suppressor. For example, when a user logs into the system and they are authenticated with multi-factor authentication, there is often a timeline event that displays that information.
Updated about 1 year ago